Setting up for High Availability#
Introduction#
The Arthur Platform is built to run in a High Availability configuration, ensuring that the application can function in the event of a Data Center outage, hardware outages, or other similar infrastructure issues.
In order to take advantage of this, there are a few requirements in how your infrastructure is setup:
Installing across 3 Availability Zones
Specifying the correct Instance Types
Configuring the cluster for Auto-scaling
Notes about this document#
Note
Note that this document is written using AWS terminology, as this is one of the environments/infrastructure that Arthur uses internally for our environments. However, these setup steps should work across various cloud providers using similar features.
Note
Note that this document is written with the pre-requisite that you are installing Arthur in a High Availability configuration. At the minimum, this means that there should be 3 instances across which Arthur is deployed.
Installing across 3 Availability Zones#
In order to ensure continuous operation during an Availability Zone (AZ) outage, Arthur must be installed on a cluster that has 3 Availability Zones. This ensures that in the event of one AZ outage that the rest of the components can still operate.
To do this in AWS, create 3 separate Auto-Scaling Groups (ASGs) - one for each AZ.
To enable this in the installer admin page please select the following options:
Select “Enable Rack Awareness”

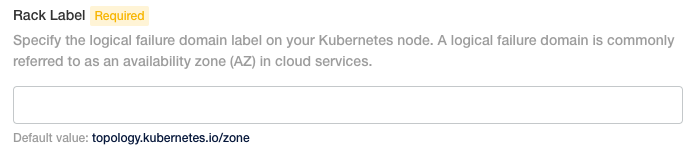
Configure “Rack Label” if necessary
Most kubernetes installations use the default label “topology.kubernetes.io/zone” to specify AZs. If your installation does not please specify your label here
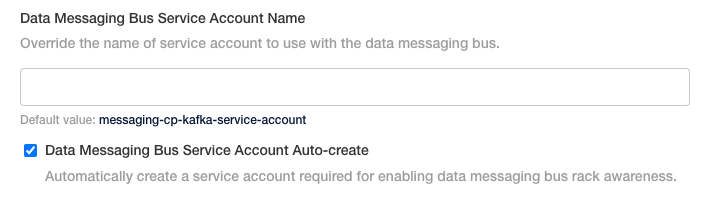
Messaging Bus Service Account
Unless you specified a different name for the messaging bus, select “Data Messaging Bus Service Account Auto-create”
Specifying the correct Instance Types#
Generally speaking, the best way to ensure you have deployed the correct Instance Types is to monitor resource utilization across the cluster to determine when your services are hitting resource limits.
When initially configuring a cluster for Arthur, we recommend 3 nodes, where each node has at least 16 vCPUs and 64G of RAM (eg: an m5a.4xlarge instance type).
This is a good starting point for a general-purpose cluster that will grow with your production usage.
Configuring the cluster for Auto-scaling#
Arthur’s stateless components horizontally auto-scale, but in order to take the maximum advantage of this, you will need to configure and install an additional component that performs node autoscaling (eg: adding more instances).
AWS specifies how to setup cluster autoscaling in their documentation.
Generally speaking, it involves setting up an IAM role and granting permissions to autoscale the cluster, and then installing a third-party component to perform the autoscaling (eg: cluster-autoscaler
Configure dedicated Kubernetes Node Groups for the OLAP Database#
If you have a very high throughput environment and want to run Arthur in its most performant setup, you can dedicate specific nodes for the OLAP Database.
To do this you will need to configure your kubernetes cluster to have node groups with dedicated taints and tolerations.
Once this is setup you can specify the OLAP Database label keys and values in the config page. The below key and value is just an example:
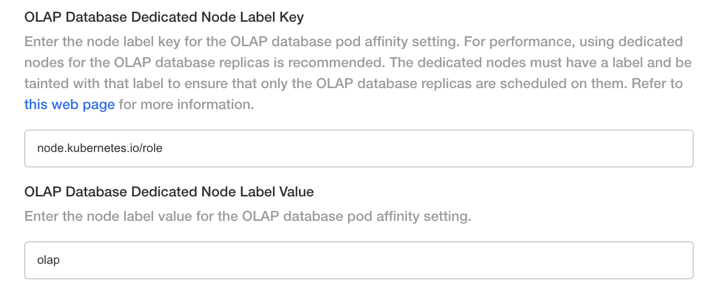
When running in dedicated node groups you should also follow the above steps to ensure that the OLAP Database is running across multiple availability zones. A common way to set this up would be to create separate node groups for each availability zone, with each of the separate node groups having the same taints and tolerations