Basic Concepts#
Arthur Overview#
The Arthur platform monitors, measures, and improves machine learning models to deliver better business outcomes. Arthur helps data scientists, product owners, and business leaders accelerate model operations and optimize for accuracy, explainability, and fairness.
To use Arthur, you:
Register your model with the Arthur system
Set reference data for baseline analytics
Send inference data over time
With this data, Arthur quantifies and centralizes your models’ performance for efficient querying and automated analytics.
Models and Onboarding#
Registering a Model#
When you register a model with Arthur, you define the way the model processes data. Arthur is model-agnostic and platform-agnostic, so no matter which tools you used to build or deploy, you can use Arthur to log all the data your model receives and produces - registration tells Arthur how this will happen.
Input and Output Types#
These are the data types that define the data that enters and exits your model.
The InputType of a model specifies whether data enters your model as a tabular dataframe, as an image, or as raw text.
The OutputType of a model specifies the modeling task at hand:
whether your model is predicting values for a regression task, predicting probabilities for a classification task,
or predicting bounding boxes for a computer vision object-detection task.
Streaming vs. Batch#
When registering a model, you specify whether your model ingests data either as a stream or in batches. A streaming model receives instances of data as they come into the deployed model. A batch model, in contrast, receives data in groups, and is often preferred if your model runs as a job rather than operating in realtime or over a data stream.
Indicating a batch model simply means that you’ll supply an additional “batch_id” to group your inferences, and Arthur will default to measuring performance for each batch rather than by the inference timestamps.
Attributes and Stages#
Attributes are analagous to the different columns that make up your model’s data.
Each attribute has a value type: these can be standard types like int and str,
or datatypes for complex models like raw text and images.
When you are onboarding a model, Arthur categorizes each attribute into a different Stage,
depending on the role of the attribute in the model pipeline:
ModelPipelineInput: these attributes are the features your model receives as inputPredictedValue: these attributes are the output values your model producesGroundTruth: these attributes are the true values for your model’s prediction task, for comparing the model’s outputs against for performance metricsNonInputData: these attributes are the additional metadata you can log with Arthur related to input data that your model doesn’t take as an input feature, e.g. protected attributes like age, race, or sex, or specific business data like a unique customer ID
Model Schema#
The model schema is a record of important properties of your model’s attributes, including their value type and Stage.
As you log data over time with Arthur, the model schema is used to type-check ingested data.
This prevents analytics from being skewed by scenarios
like int values suddenly replacing float values causing silent bugs.
Arthur also records attribute properties in the model schema, like the range of possible values an attribute has in your data. These properties are used to get a sense of your data’s high-level structure, not to enforce that future attributes have strictly these same properties.
Reference Dataset#
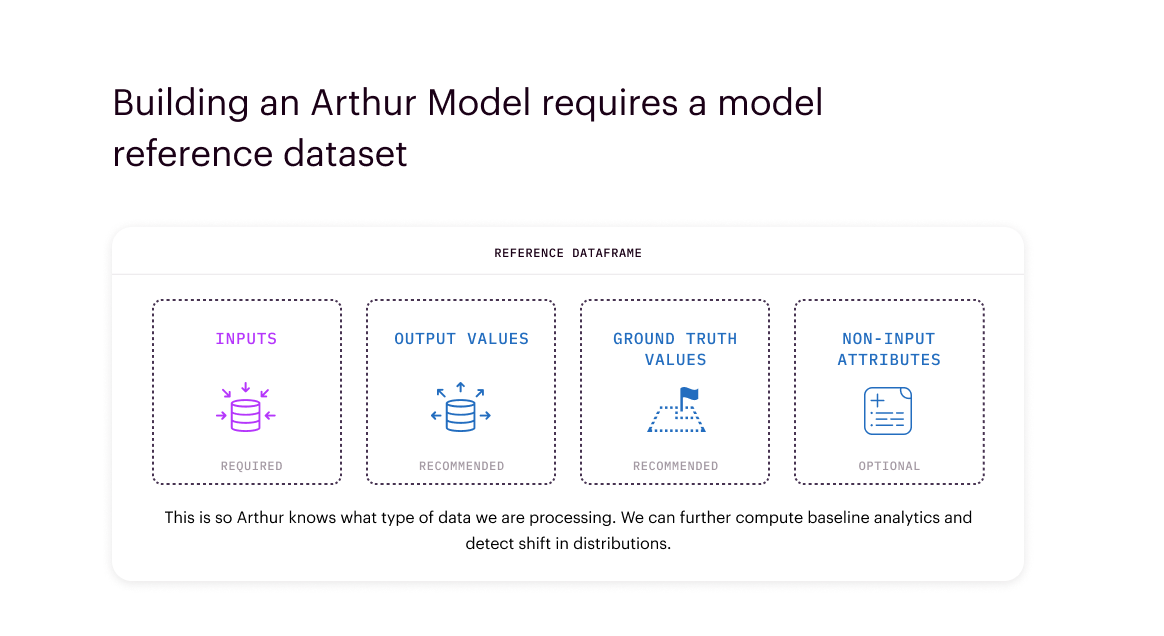
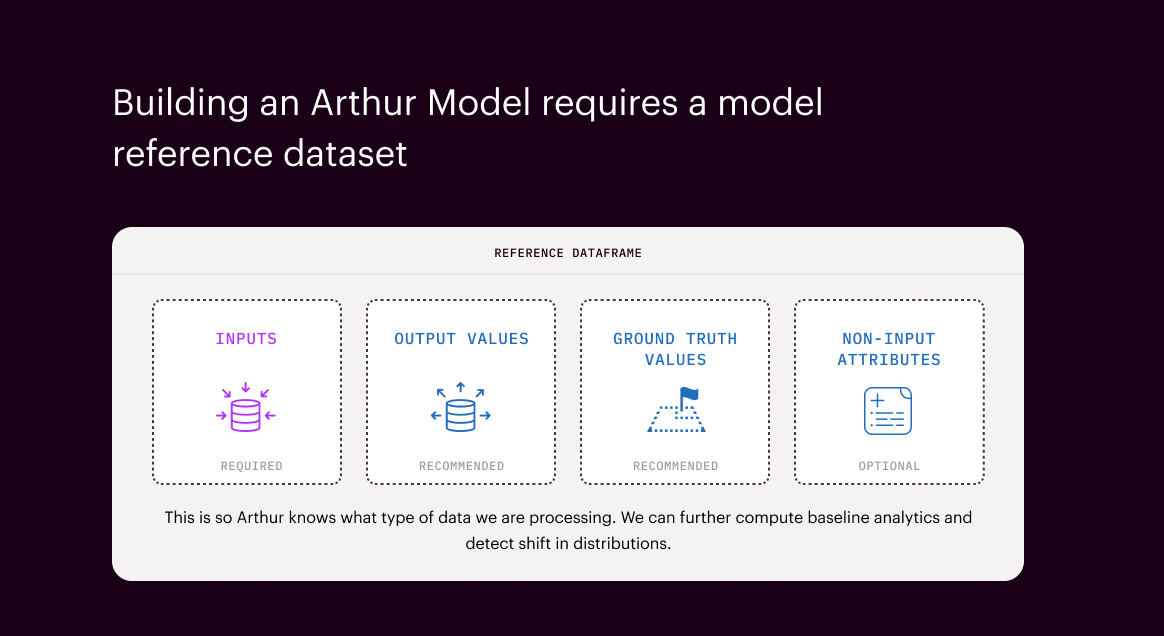
The reference dataset is a representative sample of the input features your model ingests. This can be the model’s training data, or any other set of data that captures the distribution of data your model’s inputs are sourced from.
This dataset is used to compute baseline model analytics. By capturing the distribution of data you expect your model to receive, Arthur can detect, surface, and diagnose data drift before it impacts results. Note that Arthur can compute data drift metrics against any two distributions you choose (e.g. inferences now compared to the same time last year), but the platform uses the reference dataset as the default.
The only required stage to be included in the reference dataset is ModelPipelineInput.
But we also recommend including data from the PredictedValue, GroundTruth, and NonInputData stages so that
Arthur can measure drift in those attributes over time as well.
Onboarding Status#
Once you onboard a model, the Arthur platform will create the model and provision the necessary infrastructure to enable data ingestion for that model. During the creation process, your model will go through the following statuses:
1. Pending
If your model status is Pending, this means model creation will begin soon. Please check back for updates or contact support if you don’t see any updates within a few minutes.
2. Creating
If your model status is Creating, this means the model creation process is in-progress. Please check back for updates or contact support if you don’t see any updates within 10 minutes.
3. Ready
If your model status is Ready, the model creation process completed successfully! Your model is now ready to ingest data.
4. Creation Failed
If your model status is Creation Failed, the model creation process was not successful and the necessary infrastructue was not provisioned fully. While in this state, your model will not be able to ingest any data. You may try re-saving the model or contact support if the problem persists.
Sending Data to Arthur#
Inferences#
The data your model produces over time is logged in the Arthur platform as inferences.
These inferences contain attributes from the ModelPipelineInput and PredictedValue stage (model inputs and outputs),
from which Arthur computes performance metrics. In addition, when you log these inferences,
you have the option to include GroundTruth and NonInputData attributes.
Sending Ground Truth Separately#


GroundTruth attributes are often not available when models produce inferences.
Therefore, Arthur allows you to send this attribute data to the platform after sending the original inferences,
using an ID to pair data with the right inference.
Metrics#
Metrics are the measurements Arthur computes to quantify model performance. Default metrics are the basic model performance metrics generated automatically by Arthur, e.g. accuracy, mean-squared error, or AUC. Furthermore, additional metrics can be written using the API and added to a model for measuring performance specific to a custom business use-case.
You can use the Arthur API to efficiently query model performance metrics at scale. Model metrics can be accessed in the online Arthur UI, using the Arthur API, and by using the Arthur Python SDK.
See the API Query Guide for more resources on model metrics.
Alerts#
An alert is a message notifying you that something has occurred with your model. With alerts, Arthur makes it easy to provide a continuous view into your model by highlighting important changes in model performance.
An alert is triggered based on an alert rule, which you define using a metric and a threshold: when the metric crosses your threshold, the alert is activated. This alert can then be delivered to you via email, highlighted in the online Arthur UI, and/or accessed via integrations such as PagerDuty and Slack.
For an in-depth guide to setting alerts, see the Metrics & Alerts guide.
Enrichments#
Enrichments are additional services that the Arthur platform provides for state-of-the-art proactive model monitoring:
Explainability: methods for computing the importance of individual features from your data on your model’s outcomes.
Anomaly Detection: drift metrics for quantifying how far incoming inferences have drifted from the distribution of your model’s reference dataset.
Hotspots: automated identification of segments of your data where your model is underperforming.
Bias Mitigation: methods for model post-processing that improve the fairness of outcomes without re-deploying your model.
Once activated, these enrichments are computed on Arthur’s backend automatically, with results viewable in the online UI dashboard and queryable from Arthur’s API.
The Enrichments guide shows how to set up enrichments and describes all of Arthur’s currently offered enrichments.
Insights#
Insights are proactive notifications about your model’s performance. For example, once you’ve enabled the Hotspots enrichment you’ll receive insights about regions of your data space where model accuracy has significantly degraded.
Model Groups and Versioning#
Arthur helps you track the improvements of model updates with Model Versioning.
If a change has occurred to your data preprocessing pipeline, if you have retrained your model, or if you’ve reset your model’s reference data, your updated model is likely a new version of a previous model addressing the same task. In this case, Arthur recommends keeping these models within the same Model Group to track performance as you continue improving your model.
Each model you onboard to Arthur is placed in a Model Group. As you change the model over time, you can add new versions of the model that will live in the same group. Tracking improvement in performance over time within a Model Group is then streamlined for quick insights in the Arthur UI dashboard.
Next Steps#
Onboard Your Model#
The Model Onboarding walkthrough covers the steps of onboarding a model, formatting attribute data, and sending inferences to Arthur.